Im folgenden Beitrag stellen wir einen Ansatz zum Vergleich der Wiener Zeitung und des Salzburger Intelligenzblatts im 18. Jahrhundert vor. Dabei erproben wir die digitale Methode des Topic Modelling, mithilfe dessen die (thematische) Struktur der Texte erforscht und verglichen werden kann.
Autor: Thomas Kirchmair

Die Wiener Zeitung (WZ) wird seit 1703 veröffentlicht und gilt als die älteste noch erscheinende Zeitung der Welt. Sie wird im 18. Jahrhundert posttäglich, also mittwochs und samstags, veröffentlicht (Berger, 1953). Inhaltlich fokussiert sich die Wiener Zeitung auf Informationen für Adelige wie etwa amtliche Kundmachungen, Geschehnisse in der Stadt und Inserate, ebenso wie (internationale) politische Begebenheiten (Mader-Kratky, Resch & Scheutz, 2019). Das Salzburger Intelligenzblatt (SZ) hingegen stellt eine Beilage zur Oberdeutschen Zeitung dar und erscheint ab 1784 in einem wöchentlichen Rhythmus. Thematisch enthält es amtliche Kundmachungen, nützliche und belehrende Artikel mit ökonomischen oder geschichtlichen Schwerpunkten und diverse Inserate und Anzeigen. Zusätzlich verfügen manche Ausgaben über unterhaltende Artikel, etwa zu Mode und Kunst. (Demelmair, 2011)
Untersucht wurde der Zeitraum zwischen 1789 und 1799, da von den Anfangsjahren des Salzburger Intelligenzblatts nur geringe Textmengen digital verfügbar sind. vorhanden sind. Die beiden Datensets wurden aus dem ANNO-Bestand (Austrian Newspapers Online) bezogen. Sie umfassen die Volltexte, nicht jedoch die ebenso verfügbaren Faksimiles. Die Wiener Zeitung beinhaltet in diesem Zeitraum 1304 Ausgaben, das Salzburger Intelligenzblatt 630. Die genaue Verteilung der Ausgaben pro Jahr ist in Abbildung 2 ersichtlich.

Um die Texte verarbeiten zu können, müssen diese tokenisiert werden. Dabei wird der Zeichenstrom in kleinere Einheiten, sogenannten Tokens („Laufwörter“), zerlegt (Webster & Kit, 1992). Das Korpus der Wiener Zeitung umfasst 34.126.677 Tokens, das Korpus des Salzburger Intelligenzblatts umfasst 3.031.989 Tokens. Die Daten werden in einem nächsten Schritt aufbereitet, um sie für das Topic Modelling verwenden zu können. Der gesamte Code als Jupyter Notebook und Nachweise der ausgewählten Ausgaben sind im GitLab der ÖNB Labs verfügbar.1
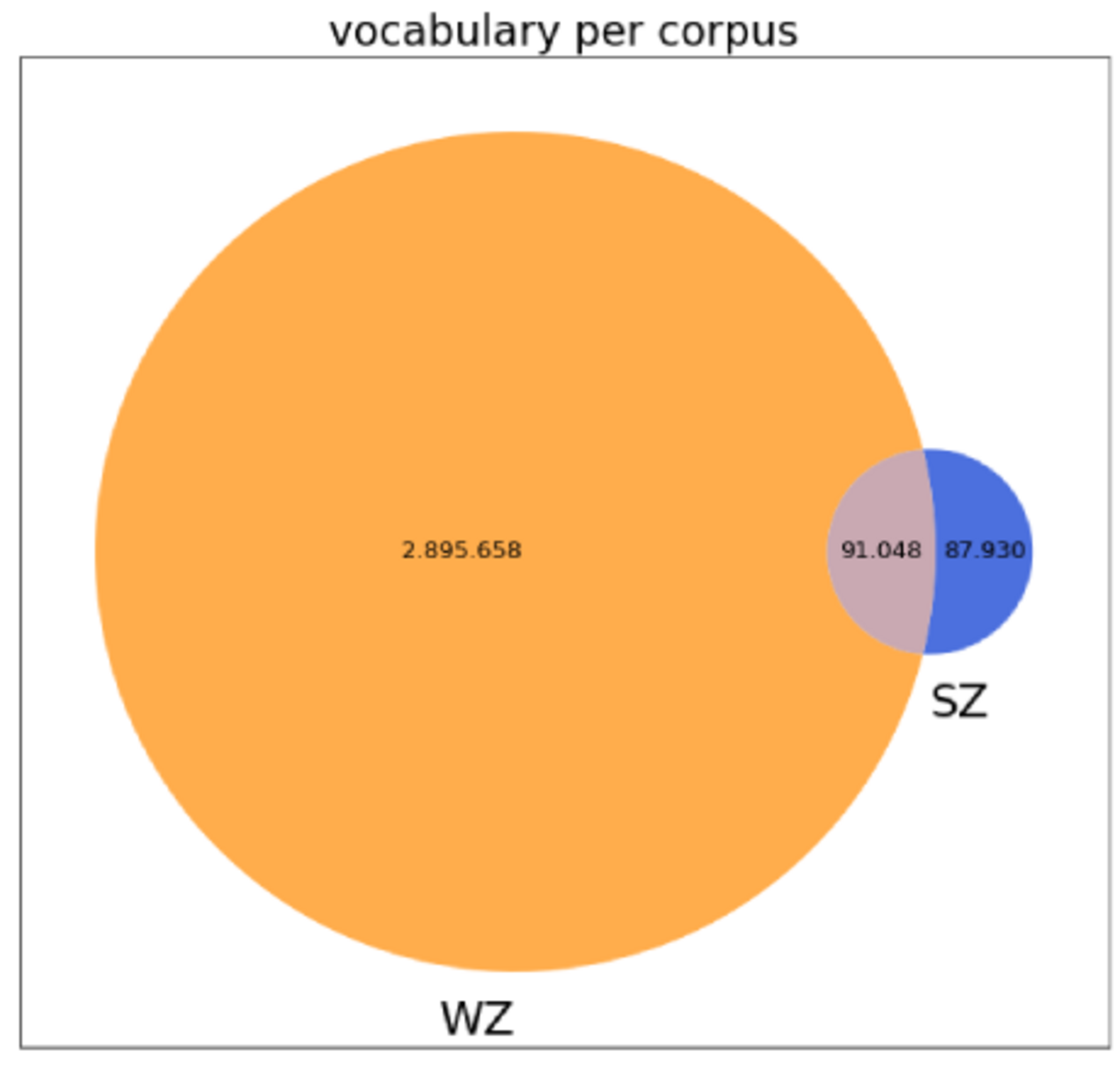
Um Korpora vergleichen zu können, gibt es verschiedene Methoden, viele davon können jedoch nur bedingt für historische Textdaten verwendet werden. So können wir etwa den Wortschatz der beiden Korpora vergleichen. Das unterschiedliche Vokabular von Wiener Zeitung und Salzburger Intelligenzblatt können wir mithilfe eines Mengendiagramms grafisch darstellen, wie in Abbildung 3 ersichtlich ist.
Dabei zeigt sich, dass das Vokabular der Wiener Zeitung sehr viel größer ist als jenes des Salzburger Intelligenzblatts. Während sich das Salzburger Intelligenzblatt 50.87 % des Vokabulars mit der Wiener Zeitung teilt, sind es umgekehrt lediglich 3.05 % des Vokabulars, das sich die Wiener Zeitung mit dem Salzburger Intelligenzblatt teilt. Ein weiterer, relativ neuer Ansatz zum Vergleich von Korpora ist die Berechnung der semantischen Ähnlichkeit, bei der Dokumente zu Vektoren basierend auf Wortfrequenzen umgewandelt werden und deren Differenz berechnet wird. Diesem Ansatz nach sind die beiden Korpora zu 9.53 % semantisch ähnlich. Allerdings bieten diese Methoden keine Möglichkeit, inhaltliche oder strukturelle Merkmale der Texte zu erfassen. Aus diesem Grund wurde ein Ansatz mittels Topic Modelling erprobt.
Unter Topic Modelling werden verschiedene Verfahren der natürlichen Sprachverarbeitung zusammengefasst, die automatisch Topics aus Textdaten extrahieren. Dabei werden Tokens die häufiger gemeinsam auftreten zu Topics zusammengefasst. Hierbei muss angemerkt werden, dass Topics nicht zwingend mit Themen im engeren Sinne gleichgesetzt werden können, da sie auf statistischen Berechnungen basieren. Die bekannteste und am einfachsten zu implementierende Methode, das Latent Dirichlet Allocation Model, kurz LDA, stammt von Blei, Ng & Jordan (2003). Topic Modelling wird in vielen verschiedenen Bereichen eingesetzt, unter anderem etwa für die Analyse historischer Dokumente, wissenschaftlicher Publikationen und Literatur, in den computergestützten Sozialwissenschaften und in der maschinellen Translation (Boyd-Graber, 2017). Da die Daten in ANNO durch ein OCR-Verfahren gewonnen wurden, wird jedoch ein sogenanntes Embedded Topic Model (ETM) verwendet. Die Textqualität bei automatisch digitalisierten Texten ist schwankend, etwa aufgrund von Sprachvariation, historischen Schriftarten oder der materiellen Qualität der Datenträger (Österreichische Nationalbibliothek, 2022). Das ETM-Modell jedoch ist gegenüber fehlerbehaftetem Text und einem großen Vokabular robuster als das klassische LDA-Modell (Zosa et al., 2021). Das ETM-Modell stellt eine Weiterentwicklung des LDA-Modells dar, zusätzlich werden hierbei Wortvektoren verwendet, wodurch aussagekräftigere Ergebnisse generiert werden können.
Nachdem die Daten, bestehend aus dem jeweiligen Korpus und dem dazugehörigen Vokabular, aufbereitet wurden, wird das Modell im sogenannten OCTIS-Framework implementiert, welches die automatische Evaluation der Ergebnisse ermöglicht (Terragni, Fersini, Galuzzi, Tropeano & Candelieri, 2021). Die unterschiedlichen Parameter der Algorithmen können darin automatisch initialisiert und manuell angepasst werden, so können bestmögliche Resultate erzielt werden. Anschließend wurde pro Zeitungskorpus ein Modell trainiert.
Aus der Wiener Zeitung wurden 99 Topics extrahiert, aus dem Salzburger Intelligenzblatt 66. Wir interpretieren die Topics manuell und ordnen diese verschiedenen Kategorien zu, die aus dem Material abgeleitet werden. Daneben gibt es auch Topics, die nicht sinnvoll interpretiert werden können, da sie aus Tokens bestehen, die nur aufgrund statistischer Inferenzen ein Topic bilden, jedoch keine kohärente Sinnstruktur aufweisen (z.B. ‚anna bevor jahr freye feld widrige such klara eigenschaft märz‘). Diese werden aus der Analyse ausgeschlossen. Ausgehend von feineren Themen wird interpretativ auf gröbere Themen rückgeschlossen. Insgesamt konnten wir 46 verschiedene Themen identifizieren, 17 davon sind ausschließlich in der Wiener Zeitung, 19 ausschließlich im Salzburger Intelligenzblatt, und zehn in beiden Periodika zu finden. Die Verteilung der Topics ist in der Abbildung 4 ersichtlich. Anzumerken ist hierbei jedoch, dass deren Häufigkeit im Diagramm nicht berücksichtigt wird.
Dabei wird ersichtlich, dass die Wiener Zeitung und das Salzburger Intelligenzblatt viele Themen teilen, allerdings in einem unterschiedlichen Ausmaß. In Abbildung 5 sind die am stärksten divergierenden Themen grafisch dargestellt. Diese sind Grundlage der weiteren Interpretation.

So legen die Ergebnisse der Modelle etwa nahe, dass in der Wiener Zeitung mehr ‚advertisements‘, also Inserate, enthalten sind als im Salzburger Intelligenzblatt. Daneben gibt es auch Themen, die lediglich in einer Zeitung auftreten, wie etwa ‚educational texts‘ und ‚rumours‘ im Salzburger Intelligenzblatt oder ‚work‘ und ‚insolvency‘ in der Wiener Zeitung. Generell zeigt sich, dass in der Wiener Zeitung vermehrt Themen enthalten sind, die tendenziell als eher faktenbasiert und staatsbezogen („hard news“) eingeordnet werden können (‚legal issues‘, ‚military‘, ‚politics‘, ‚work‘, ‚insolvency‘, ‚state‘, ‚obituary‘, ‚trade‘, ‚economic issues‘). Im Salzburger Intelligenzblatt treten hingegen tendenziell eher meinungsbasierte und personenbezogene Themen auf („soft news“), wie etwa ‚educational text‘, ‚medicine‘,‘ rumour‘, ‚societal issues‘, ‚craftsmanship‘ oder ‚health‘. Diese Ergebnisse stehen mit den bisherigen Forschungen im Einklang, die die Wiener Zeitung als eher staatsorientiert, das Salzburger Intelligenzblatt als aufklärerisch beschreiben (vgl. Mader-Kratky, Resch & Scheutz, 2019; Demelmair, 2011).
Durch den innovativen Ansatz konnten wir zeigen, dass zum Vergleich historischer Dokumente Topic Modelling als Methode geeignet ist. Dabei ist historisches (Sprach-)Wissen unerlässlich, da sich die Interpretation der Topics als sehr komplex darstellt. Die Vertrautheit mit dem Material ist daher zur Interpretation der Ergebnisse eine notwendige Voraussetzung. Darüber hinaus müssen die Topics mit Vorsicht interpretiert werden, da die Ergebnisse des Models nur Ausschnitte aus der Gesamtheit der Daten darstellen. So kann es etwa vorkommen, dass aufgrund geringer oder fehlender statistischer Häufung von Tokens keine Topics gebildet werden, obwohl diese zur Interpretation der Daten durchaus beitragen könnten. Daher müssen die erhaltenen Häufigkeiten eher als Tendenzen wahrgenommen werden, weniger als absolute Werte. Um die Qualität der Ergebnisse zukünftig zu erhöhen würde es sich anbieten, das dem ETM-Algorithmus zugrundeliegende, vortrainierte Sprachmodell, das aktuell noch auf modernen Texten basiert, durch ein Modell zu ersetzen, welches an historischen Daten trainiert wurde. Nichtsdestotrotz weist die Methode ein großes Potenzial zur Untersuchung weiterer, auch größerer Korpora digitaler Bestände historischer Periodika auf, wie sie die Österreichische Nationalbibliothek anbietet.
Eine vertiefende Beschreibung des technischen Vorgehens finden Sie auf der Seite der ÖNB Labs.
Über den Autor: Thomas Kirchmair, Bakk. BA absolvierte im Sommer 2022 ein zweimonatiges Praktikum in der Hauptabteilung Digitale Bibliothek.
1 https://labs.onb.ac.at/gitlab/thomkir1/topic-modelling-for-historical-corpus-comparison
Berger, M. (1953). „Wiennerisches Diarium“ 1703–1780. Ein Beitrag zur Entwicklung des Verhältnisses zwischen Staat und Presse. Dissertation: Universität Wien.
Blei, D. M., Ng, A. Y. & Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research 3, 993-1002. DOI: 10.5555/94491
Boyd-Graber, J. (2017). Applications of Topic Models. Foundations and Trends® in Information Retrieval, 11(2-3), 143-296. DOI:10.1561/1500000030
Demelmair, E. (2011). Kultur- und Begriffstransfer zwischen dem Fürstentum Salzburg und dem revolutionären Frankreich um 1800. Masterarbeit: Universität Wien.
Mader-Kratky, A., Resch, C. & Scheutz, M. (2019). Das Wien[n]erische Diarium im 18. Jahrhundert. Neue Sichtweisen auf ein Periodikum im Zeitalter der Digitalisierung. In Mader-Kratky, A., Resch, C. & Scheutz, M. (eds), Das Wien[n]erische Diarium im 18. Jahrhundert. Digitale Erschließung und neue Perspektiven (Teil I). Wiener Geschichtsblätter 74(2), 93-113.
Österreichische Nationalbibliothek (2022). Austrian Books Online. www.onb.ac.at/en/digital-reading-room/austrian-books-online-abo (24.08.2022)
Terragni, S., Fersini, E., Galuzzi, B. G., Tropeano, P. & Candelieri, A. (2021). OCTIS: Comparing and Optimizing Topic models is Simple!. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, 263–270. DOI: 10.18653/v1/2021.eacl-demos.31
Webster, J. J. & Kit, C. (1992). Tokenization as the initial phase of NLP. COLING '92: Proceedings of the 14th conference on Computational linguistics 4, 1106-1110. DOI: 10.3115/992424.992434
Zosa, E., Mutuvi, S., Granroth-Wilding, M. & Deucet, A. (2021). Evaluating the Robustness of Embedding-based Topic Models to OCR Noise. In Ke, H.R., Lee, C.S. & Sugiyama, K. (eds), Towards Open and Trustworthy Digital Societies. ICADL 2021. Lecture Notes in Computer Science 13133, 392-400, Springer. DOI: 10.1007/978-3- 030
Bitte beachten Sie die Öffnungszeiten zu den Feiertagen.